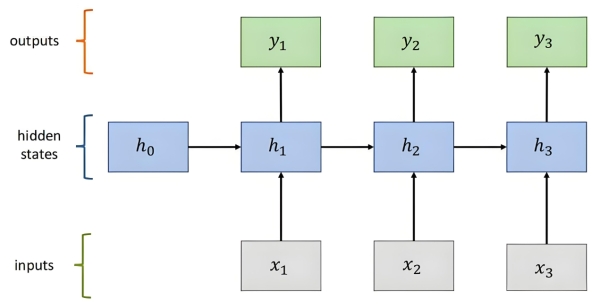
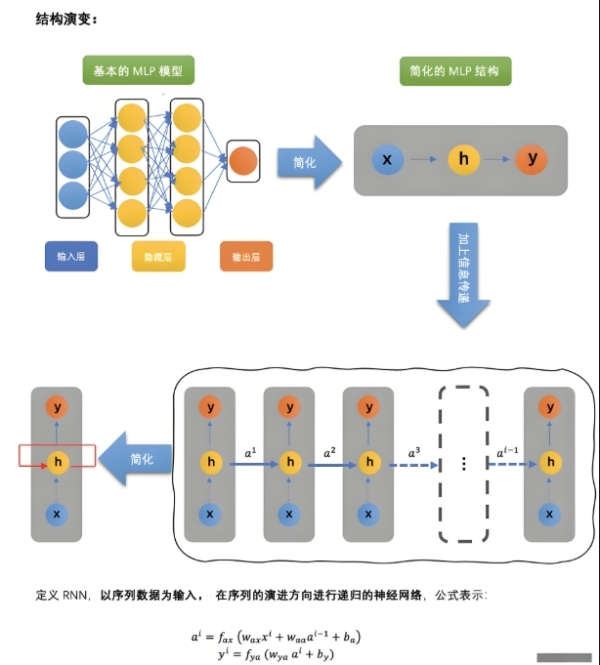
传统神经网络(如 CNN、全连接网络)的输入是独立的(无顺序关系),而 RNN 通过循环连接保存历史信息,使当前输出不仅依赖于当前输入,还依赖于之前的 “记忆”。例如:
- 预测句子中下一个词时,需依赖前文已出现的词;
- 预测股票价格时,需参考过去几天的价格走势。
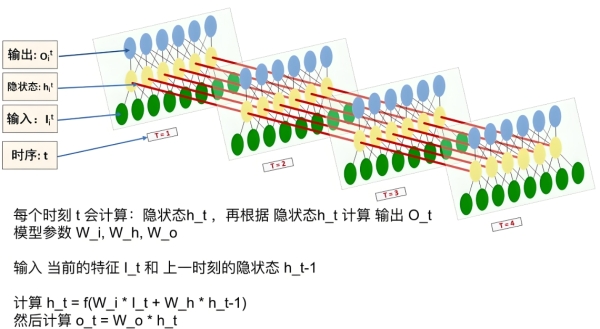
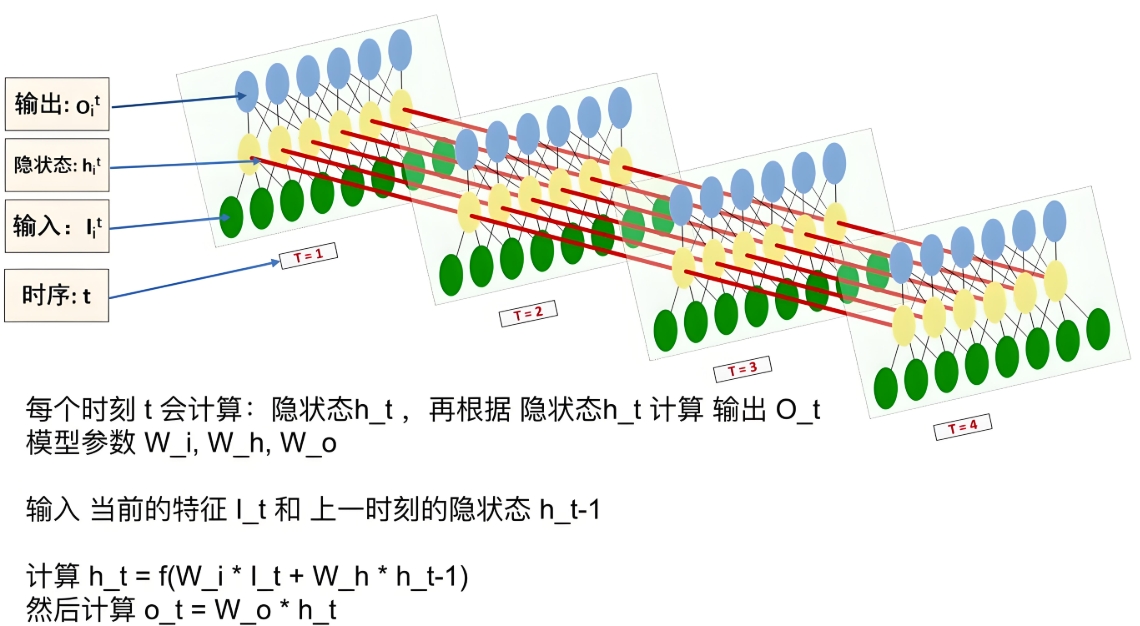
RNN 的基本单元(Cell)包含两个输入:当前时刻的输入\(x_t\)和上一时刻的隐藏状态\(h_{t-1}\)(即 “记忆”),输出当前隐藏状态\(h_t\)和预测值\(y_t\)。
隐藏状态更新公式:
\(h_t = \tanh(W_{xh}x_t + W_{hh}h_{t-1} + b_h)\)其中,
\(W_{xh}\)是输入到隐藏层的权重,
\(W_{hh}\)是隐藏层到自身的循环权重,
\(b_h\)是偏置,
\(\tanh\)是激活函数(将输出限制在 [-1,1])。
输出层公式(以分类为例):
\(y_t = \text{softmax}(W_{hy}h_t + b_y)\)<img src="https://i.imgur.com/RnOGz4q.png" alt="RNN结构展开图" width="500">
当序列过长(如长句子、长时间序列),RNN 在反向传播时会出现梯度消失或梯度爆炸:
- 梯度消失:早期时刻的信息对当前输出的影响被 “稀释”,无法捕捉长距离依赖(如文本中 “前文提到的人物” 与 “后文代词” 的关联)。
- 梯度爆炸:梯度值过大导致模型参数更新不稳定。这使得基础 RNN 仅能处理短序列,难以应对实际场景中的长序列任务。
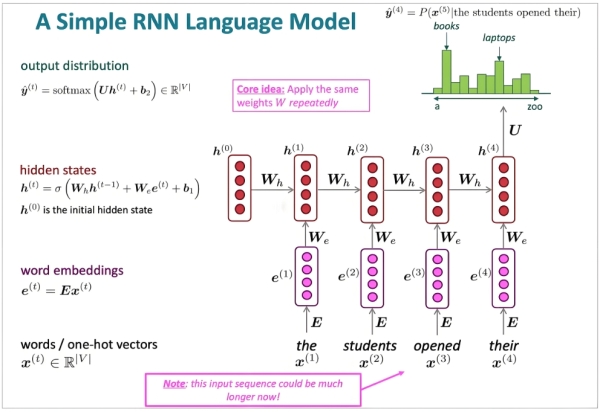
LSTM 通过门控机制(Gates)选择性地 “记忆” 重要信息、“遗忘” 无关信息,有效缓解了梯度消失问题,能够捕捉长序列中的依赖关系。
LSTM 的 Cell 包含遗忘门、输入门、输出门和细胞状态(Cell State),其中细胞状态类似 “传送带”,负责长期信息的稳定传递。
通过细胞状态的稳定传递和门控的选择性过滤,LSTM 能保留序列中早期的关键信息(如一篇文章的主题),并在后续时刻有效利用这些信息,解决了 RNN 的梯度消失问题。
GRU 是 LSTM 的轻量化变体,通过合并门控单元减少参数数量,在保持性能接近 LSTM 的同时提升计算效率,更适合资源有限的场景。
GRU 取消了 LSTM 的 “细胞状态”,仅保留隐藏状态\(h_t\),并将 “遗忘门” 和 “输入门” 合并为更新门,新增重置门:
更新门(Update Gate):决定保留多少历史隐藏状态
\(h_{t-1}\)和吸收多少新信息,输出范围 [0,1]:
\(z_t = \sigma(W_z [h_{t-1}, x_t] + b_z)\) 重置门(Reset Gate):决定如何将历史隐藏状态与当前输入结合生成新信息,输出范围 [0,1](0 表示完全忽略历史):
\(r_t = \sigma(W_r [h_{t-1}, x_t] + b_r)\) 隐藏状态更新:
- 候选隐藏状态(新信息):\(\tilde{h}_t = \tanh(W_h [r_t \odot h_{t-1}, x_t] + b_h)\)
- 最终隐藏状态:\(h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t\)
<img src="https://i.imgur.com/Jn4XxHk.png" alt="GRU结构示意图" width="400">
(GRU细胞结构:通过更新门和重置门控制隐藏状态的更新)
GRU 参数比 LSTM 少约 1/3,训练速度更快,在多数序列任务(如文本分类、机器翻译)中性能与 LSTM 接近,是实际应用中的常用选择。
RNN、LSTM、GRU 均适用于序列数据,但因特性不同,适用场景略有侧重:
其他常见应用:
- 时间序列预测(股票价格、电力负荷);
- 自然语言处理(NER 命名实体识别、文本摘要、问答系统);
- 视频分析(动作识别、帧预测)。
- 天然适配序列数据,能捕捉时序依赖关系;
- 灵活性高,可处理变长序列(输入 / 输出长度可不同,如机器翻译中 “中→英” 句子长度不同)。
- 训练效率低:按时间步串行计算,难以并行化(与 CNN 的并行计算不同);
- 对超参数敏感:学习率、隐藏层维度、序列长度等需仔细调优;
- 仍受限于 “有限记忆”:虽缓解长程依赖,但极端长序列(如万字文章)仍可能丢失早期信息。
主流深度学习框架均支持 RNN 及其变体:
- Python:
TensorFlow/Keras:layers.SimpleRNN、layers.LSTM、layers.GRU(高层 API,易用性强);PyTorch:nn.RNN、nn.LSTM、nn.GRU(底层可控性高,适合定制化需求);
- 其他:
MXNet、JAX(支持高效并行训练)。

 13867128415
13867128415
 首页
首页
 数据采集
数据采集
 数据处理
数据处理
 联系我们
联系我们