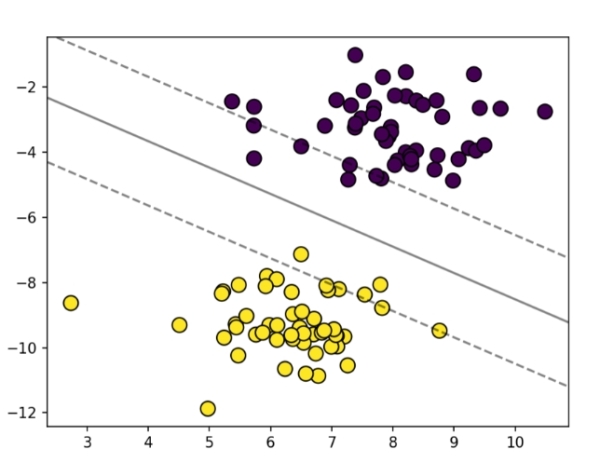
SVM 的核心目标是找到最优超平面,使两类样本间的 “间隔” 最大,从而实现高效分类。
- 超平面:在n维特征空间中,超平面是\((n-1)\)维的线性子空间,表达式为\(\boldsymbol{w}^T\boldsymbol{x} + b = 0\),其中\(\boldsymbol{w}\)是法向量(决定超平面方向),b是偏置(决定超平面位置),\(\boldsymbol{x}\)是输入样本。
- 间隔(Margin):指超平面到两类样本中最近点的距离之和(即两个平行支持超平面之间的距离)。设支持超平面为\(\boldsymbol{w}^T\boldsymbol{x} + b = 1\)和\(\boldsymbol{w}^T\boldsymbol{x} + b = -1\),则间隔为\(\frac{2}{\|\boldsymbol{w}\|}\)(\(\|\boldsymbol{w}\|\)是\(\boldsymbol{w}\)的\(L_2\)范数)。
- 支持向量(Support Vectors):距离超平面最近的样本点(落在支持超平面上),是决定超平面的关键样本,模型训练后仅依赖支持向量,与其他样本无关。
当样本线性可分时(可用超平面完美分隔),SVM 的优化目标是最大化间隔,等价于最小化\(\|\boldsymbol{w}\|^2/2\)(简化计算),同时满足分类约束:
\(\begin{align*}
&\min_{\boldsymbol{w}, b} \quad \frac{1}{2}\|\boldsymbol{w}\|^2 \\
&\text{s.t.} \quad y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b) \geq 1 \quad (i=1,2,...,n)
\end{align*}\)
其中\(y_i \in \{+1, -1\}\)为样本标签,约束确保所有样本都在超平面的正确一侧,且距离超平面至少为\(1/\|\boldsymbol{w}\|\)。
直接求解上述优化问题(原始问题)计算复杂,通过拉格朗日对偶变换可简化求解。
拉格朗日函数:引入拉格朗日乘子
\(\alpha_i \geq 0\),构造函数:
\(L(\boldsymbol{w}, b, \alpha) = \frac{1}{2}\|\boldsymbol{w}\|^2 - \sum_{i=1}^n \alpha_i [y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b) - 1]\)对偶问题转化为最大化:
\(\max_{\alpha} \sum_{i=1}^n \alpha_i - \frac{1}{2}\sum_{i=1}^n \sum_{j=1}^n \alpha_i \alpha_j y_i y_j \boldsymbol{x}_i^T \boldsymbol{x}_j\)约束:
\(\sum_{i=1}^n \alpha_i y_i = 0\),
\(\alpha_i \geq 0\)。
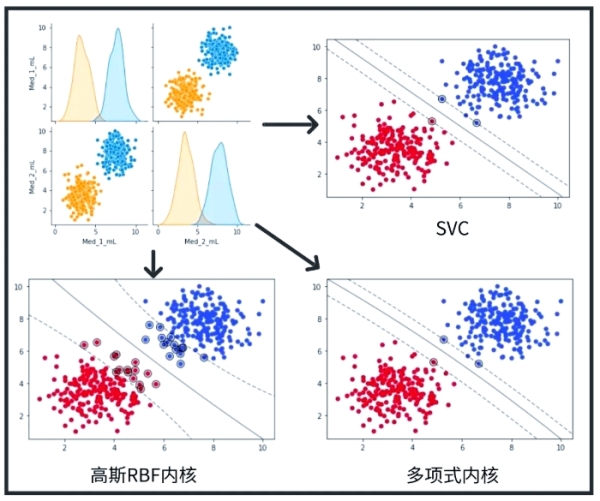
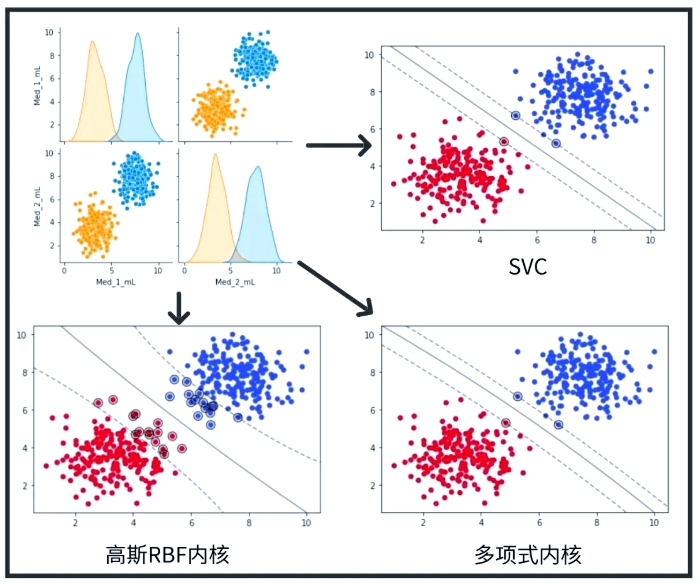
核函数的作用:当样本线性不可分时(原始空间中无超平面可完美分隔),SVM 通过核函数\(K(\boldsymbol{x}_i, \boldsymbol{x}_j)\)将样本映射到高维空间(甚至无穷维),使高维空间中样本线性可分。此时对偶问题中的\(\boldsymbol{x}_i^T \boldsymbol{x}_j\)替换为\(K(\boldsymbol{x}_i, \boldsymbol{x}_j)\),避免了直接计算高维映射(核技巧)。
常见核函数:
- 线性核:\(K(\boldsymbol{x}_i, \boldsymbol{x}_j) = \boldsymbol{x}_i^T \boldsymbol{x}_j\)(适用于线性可分数据,计算快)。
- 多项式核:\(K(\boldsymbol{x}_i, \boldsymbol{x}_j) = (\gamma \boldsymbol{x}_i^T \boldsymbol{x}_j + r)^d\)(\(\gamma, r, d\)为参数,适用于低维非线性数据)。
- 高斯核(RBF):\(K(\boldsymbol{x}_i, \boldsymbol{x}_j) = \exp(-\gamma \|\boldsymbol{x}_i - \boldsymbol{x}_j\|^2)\)(\(\gamma > 0\),适用于高维非线性数据,应用最广)。
- sigmoid 核:\(K(\boldsymbol{x}_i, \boldsymbol{x}_j) = \tanh(\gamma \boldsymbol{x}_i^T \boldsymbol{x}_j + r)\)(模拟神经网络,较少用)。
现实数据常含噪声或样本重叠,无法线性可分。软间隔 SVM 允许少量样本违反间隔约束,通过引入松弛变量\(\xi_i \geq 0\)(表示样本i的违规程度)和惩罚系数C(控制对违规的容忍度),优化目标调整为:
\(\begin{align*}
&\min_{\boldsymbol{w}, b, \xi} \quad \frac{1}{2}\|\boldsymbol{w}\|^2 + C\sum_{i=1}^n \xi_i \\
&\text{s.t.} \quad y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b) \geq 1 - \xi_i \quad (i=1,2,...,n) \\
&\quad \xi_i \geq 0
\end{align*}\)
- C越大:对违规样本惩罚越重,模型倾向于严格分类(可能过拟合)。
- C越小:允许更多违规,模型更宽松(可能欠拟合)。
SVM 本质是二分类模型,扩展到多分类(k类)需通过组合策略:
- 一对多(One-vs-Rest):训练k个二分类器,第i个分类器将第i类样本与其他类样本分开,预测时取概率最高的类别。
- 一对一(One-vs-One):训练\(k(k-1)/2\)个二分类器(每类两两配对),预测时通过投票决定最终类别(应用更广)。
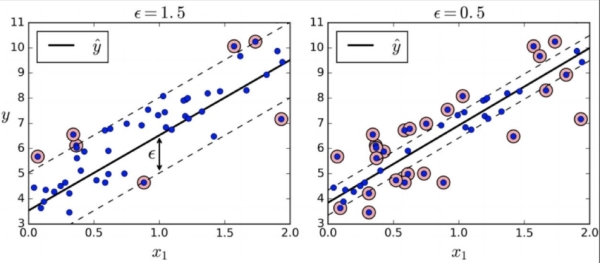
- 六、支持向量回归(SVR)
SVM 扩展到回归任务时,目标是找到一个超平面,使尽可能多的样本落在 “\(\epsilon\)- 间隔带” 内(带的宽度为\(2\epsilon\)),优化目标为:
\(\min_{\boldsymbol{w}, b, \xi, \xi^*} \quad \frac{1}{2}\|\boldsymbol{w}\|^2 + C\sum_{i=1}^n (\xi_i + \xi_i^*)\)
约束:
\(y_i - (\boldsymbol{w}^T\boldsymbol{x}_i + b) \leq \epsilon + \xi_i\),
\((\boldsymbol{w}^T\boldsymbol{x}_i + b) - y_i \leq \epsilon + \xi_i^*\),
\(\xi_i, \xi_i^* \geq 0\)。
其中
\(\xi_i, \xi_i^*\)是松弛变量,分别表示样本在间隔带下方和上方的偏差。
优点:
- 泛化能力强:基于间隔最大化,不易过拟合(尤其高维空间)。
- 灵活性高:通过核函数处理非线性问题,无需手动设计特征映射。
- 鲁棒性:仅依赖支持向量,抗干扰能力较强(当非支持向量含噪声时)。
缺点:
- 计算复杂度高:训练时间随样本量增加显著上升(适合中小规模数据)。
- 对参数敏感:核函数、C、\(\gamma\)等参数需通过交叉验证调优,否则性能波动大。
- 对缺失值和噪声敏感:需预处理数据(如归一化、去除异常值)。

 13867128415
13867128415
 首页
首页
 数据采集
数据采集
 数据处理
数据处理
 联系我们
联系我们