
 13867128415
13867128415

茶叶成分分析
无损检测:无需破坏茶叶样本,避免传统化学检测的污染和成本问题。高效快速:单样本检测时间可缩短至1秒以内,适用于生产线实时分拣。综合信息提取:同时获取茶叶外形、色泽、化学成分等多维度信息,克服单一检测手段的局限性。
项目内容
茶叶品类特性数据采集

采集参考Q/EX C 0628-2025标准
一、检测目的和依据
l 使用高光谱技术,采集不同产地茶叶水峰的光谱数据。
二、样品类别及数量
1.茶叶水峰样本:每个产地茶叶水峰若干颗
三、检测设备和方法
检测设备
1. 400-1000nm高光谱相机
2. 高光谱采集暗箱
3. 黑色托盘(低反射率背景)
4. 辅助材料:
l 标签(用于标记茶叶水峰产地)

采集方式
1. 样品摆放规则:
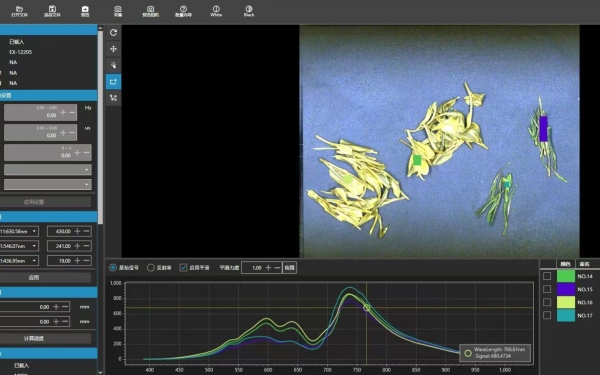
l茶叶水峰:将样品茶叶水峰按如图所示摆放。
四、采集结果
1. 数据提供
提供数据格式,每个样品数据包含如下6个格式文件:
l 样本 400-1000nm原始数据(包含 .dat、.hdr格式)
l 样本 400-1000nm反射率数据(包含 .dat、.hdr格式)
l 样本 400-1000nm高光谱图像(.png格式)
l 应客户要求:
n 另提供200条茶叶水峰光谱曲线的excel表格,每种茶叶水峰2条数据
n 提供采集设备的参数信息
n 提供数据采集过程及参数设置
2. 数据展示
茶叶水峰
- 预处理算法优化
- SG-SNV组合:SG滤波消除噪声后,SNV校正散射效应,显著提升光谱吸收峰的清晰度。实验表明,该组合预处理使SVM模型分类精度达到最优。
- 特征波段选择:采用连续投影算法(SPA)或竞争自适应加权采样(CARS)筛选关键波段,减少计算冗余。例如,SG-CARS-SVM模型仅需1.2088秒即可完成铁观音掺假检测,准确率达100%。
- 模型融合与改进
- 多特征融合:结合光谱特征与纹理特征(如GLCM参数)构建LS-SVM模型,预测集识别率提升至100%,优于单一特征模型。
- 集成学习:采用Stacking策略融合多个基础模型(如Random Forest、LightGBM),进一步提升预测鲁棒性。例如,CatBoost+Stacking模型对藏茶茶多酚含量的预测R²达0.9493。
- 可视化辅助分析
- 高光谱图像分类图:通过像素级分类生成茶叶等级空间分布图,直观展示分类结果。例如,SVM模型可清晰区分祁门红茶各等级,但边缘像素存在误分类;ELM模型误分类更严重,需进一步优化。
- 技术优势
- 无损检测:无需破坏茶叶样本,避免传统化学检测的污染和成本问题。
- 高效快速:单样本检测时间可缩短至1秒以内,适用于生产线实时分拣。
- 综合信息提取:同时获取茶叶外形、色泽、化学成分等多维度信息,克服单一检测手段的局限性。
 首页
首页
 数据采集
数据采集
 数据处理
数据处理
 联系我们
联系我们